Do you have lots of data and are unsure of how to gain value from it? Do you think computer vision models require a large investment of hours of tagging and labeling data in order to work correctly? Well, this post will shed some light on how to avoid those extensive hours and loss of valuable time by using embeddings.
AI research is moving fast to make the creation of ML models faster and less dependent on humans. How? By moving towards machine learning models purely based on existing data without the need of hand labeling in order to create datasets.
In the past, reigning Computer Vision methods required labeled data in order to train models used for, as an example, image similarity. This meant tagging thousands of images, one by one, which of course can lead to human error and it is also a huge investment of valuable time. Nowadays, however, the state of the art models in computer vision have evolved so much that you can create models used for recommender systems based on similarity, detect objects in an image and even classify them, just using unlabeled data.
Keep on reading to find out the possible ways in which the evolution of these techniques can help your business.
The main driver behind all of this are embeddings. If you are already immersed in the ML world you probably have already heard about them. Either because of how they have revolutionized natural language processings (NLP) techniques or because of the breakthroughs they are generating in computer vision. But just in case you are not familiar with the term, let’s go over the embedding basics.
What are these so-called embeddings? I don’t want to take all the fun out of it, but an embedding is just a vector (a list of numbers) that represents an image, text or other form of data. These vectors should have certain properties in order to be considered proper embeddings. Some of good embeddings characteristics are:
- Embeddings capture semantics from the input data.
- Semantically similar data will have close embeddings, while semantically dissimilar data will have distant embeddings.
- The same embeddings can be used across different models.
Let’s picture this with a quick example by describing embeddings for an e-commerce site. We have probably thousands of products which have information like price, section, name, etc and many pictures associated with it. Tabular data is easy to handle in terms of size. It is also easy to group: similar prices go together, similar brands too, and so on. But what about all the information in the images? Well, imagine an [x, y, z] vector describing an image of a mobile phone. The first coordinate represents the main color, the second the main shape and the third the logo found in the image. Similar colored phones have similar x-coordinates, the ones with similar shapes will have close y-coordinates and the brand will be represented by the z-coordinate.
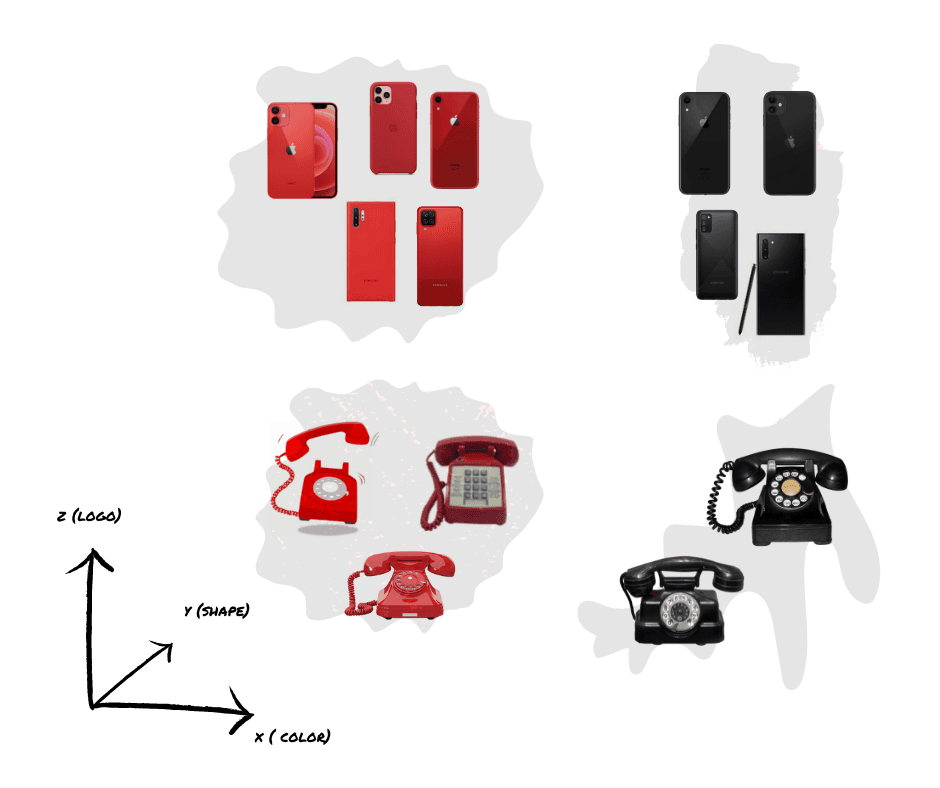
We have gone from heavy images to 3 numbers in no time. And this is what embeddings are all about! By using embeddings you can abstract the important information in an image, reducing the size and being able to easily compare this data. But that is not all. Imagine we combine this vector with the price, then we add the section and so on. It allows us to combine different types of data in an easy way.
Of course, this is just an overly simplified example for the sake of explaining the idea. We cannot abstract correctly an image’s information into only 3 numbers, but we can indeed obtain the relevant information of an image using state of the art embedding models, such as DINO or BYOL. These methods bypass the typical challenges related to computer vision models such as the amount of time required for labelling data.
Similarly, ML models can be used to obtain embeddings from other types of data, such as audio or text. As you can imagine, the amount of tasks they can be used in is enormous. Some of them include classifying images, image segmentation, and even to combine different types of data in a single model. This means you can have an embedding for an object that combines an embedding of their picture and one of their attributes, such as color, weight or brand. Not to mention the reduction in dimensions achieved by representing a whole object, movie, phone, etc as a vector.
Now, picturing how this can be done for the attributes of an object or a text might be easier than imagining it for an image. So, how can this be applied to images? Can it identify whether it has people in it? What about other objects that are present? Can it detect the texture? Well, the current state of the art allows us to identify these characteristics without making them explicit. But first, we’ll go over what had to be done to train a model before SimCLR arrived.
Image similarity or image classification algorithms used to be based on contrastive losses methods. This meant having labeled data so that the model could learn by creating far away embeddings for different classes and similar embeddings for images from the same class. Lots and lots of labeled data were required in order to obtain adequate results with the classic ResNet50 (which we still love though!). Fortunately, SimCLR (2020) appeared and since then, self-supervised methods have been improving continuously, being BYOL (2020) and DINO (2021) two of our aces up our sleeves we have used to leave some of our clients totally flabbergasted.
"A linear classifier trained on self-supervised representations learned by SimCLR achieves 76.5% top-1 accuracy, which is a 7% relative improvement over previous state-of-the-art, matching the performance of a supervised ResNet-50. When fine-tuned on only 1% of the labels, we achieve 85.8% top-5 accuracy, outperforming AlexNet with 100X fewer labels." - A Simple Framework for Contrastive Learning of Visual Representations
"While state-of-the art methods rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches 74.3% top-1 classification accuracy on ImageNet using a linear evaluation with a ResNet-50 architecture and 79.6% with a larger ResNet. We show that BYOL performs on par or better than the current state of the art on both transfer and semi-supervised benchmarks." - Bootstrap your own latent: A new approach to self-supervised Learning.
"Our method is not only better at capturing the shared information between two domains but is more generic and can be applied to a broader range of problems. The proposed framework performs well even in challenging cross-modal translations, such as video-driven speech reconstruction, for which other systems struggle to maintain correspondence." - DINO: A conditional energy based GAN domain translation.
How do self-supervised learning (SSL) methods differ from contrastive loss methods? In SSL, the model is trained to create similar embeddings for an image and an augmented version of it. By using one single image, no labels are needed! So yes, you can train an image classification model based on unlabeled data using state of the art SSL methods.
The number of ways of how these techniques can be applied to industries is immense. I’ll mention a few just to exemplify:
- Recommendation systems like the ones on movie sites. Embeddings can represent both movies and users. Similar users tend to watch similar movies. By having user-embeddings and movie-embeddings, it is possible to determine which users are similar to each other and, therefore, recommend similar movies. The same idea could be applied to recommend items based on an image similarity algorithm and even mix types of data, combining images and tabular data.
- Organize images on an ecommerce website. Just imagining the waste of time for the person selecting the front-picture, followed by the side-picture and so on gives us nightmares! This could all be automated using an image classification algorithm based on embeddings.
- Finding out information from an object’s image. Let’s say you have a huge amount of items and their related information. By using an image classification method to identify which item it is, information retrieval is much faster.
- Fast production line outlier detection can also be implemented using image classification methods. Faulty items can ruin a whole production batch and having a person looking at the manufacturing line all day long is a waste of time for both the employer and employee!!
- Automate data-grouping by applying clustering algorithms on previously created embeddings. This can be applied to segment an audience on its own or even to do the initial data-labeling step for a supervised learning algorithm.
- Finding duplicate content. Again, let’s picture an e-commerce site where users upload products. Users don't all follow the same order, picture quantity or even quality. They don’t even use the same writing syntax. How do we tackle this? By using embeddings!
We have now gone through one of the most promising techniques used in ML and the applications it can have, having covered from the basic concept of an embedding to how it can be used on image similarity and classification jobs. What is more, we have tackled the myth that ML models need huge amounts of labeled data in order to achieve state of the art results.
Want to check out these techniques in action? You can request access to our ML hub by click this link. There, we have demos of how computer vision methods can be used to automate repetitive and time consuming tasks.
Now it is your turn. Are there any repetitive image classification tasks that are worth automating? Would a recommender system boost your entrepreneurship? How can these models be used in your field? Don't hesitate to contact us and discuss all about how you can use embeddings.



