Generating good embeddings is a crucial part of the daily job of many ML engineers. Despite the fact it is a repetitive task, it is not a basic one. There are many ways to get this done. Today, we’d like to introduce you to a great tool for this purpose: Pytorch Metric Learning.
But before we go deep into a use case, let us make a small review of what this library stands for.
Metric Learning is an interesting and powerful approach to generate embeddings. This method aims to construct task-specific distance metrics from data using machine learning.
In this way, it aims to solve the problem of grouping elements with similar attributes. This can be applied to different cases such as separating visually similar objects or relating concepts (words) with similar meanings.
However, Metric Learning does have a downside: it is a huge and quite complex world. You can go deeper into this world with this tutorial or with this great survey on Deep Metric Learning.
The key parts in Metric Learning are choosing a neural network architecture to build the embeddings, and a loss function to train it with.
Here is where PyTorch Metric Learning (PML) comes into the picture. This library encapsulates many algorithms that play an important role in Metric Learning. As its author says on his site, PML contains 9 modules, each of which can be used independently within your existing codebase or combined for a complete train/test workflow.
It also includes a few examples to show how to use all of these modules in different scenarios.
In this article, we are going to use PyTorch Metric Learning to train a model with two different losses which we will compare against each other, taking advantage of many of the cool gadgets the library offers. We’ll discuss these experiments further down the road.
As we mentioned before, to apply metric learning on a problem we first need to choose a dataset to work with, a model architecture to generate the embeddings and a loss to train and improve those embeddings.
On this occasion, we chose to work with the TinyImageNet dataset. Having a significant amount of classes and images, with these last being small in size, we thought this well-known dataset would be a great fit for the scope of the experiments.
With a ResNet50 as the model architecture, we compared the results between Triplet loss and ArcFace loss. This choice wasn’t random. Both losses have their pros and cons.
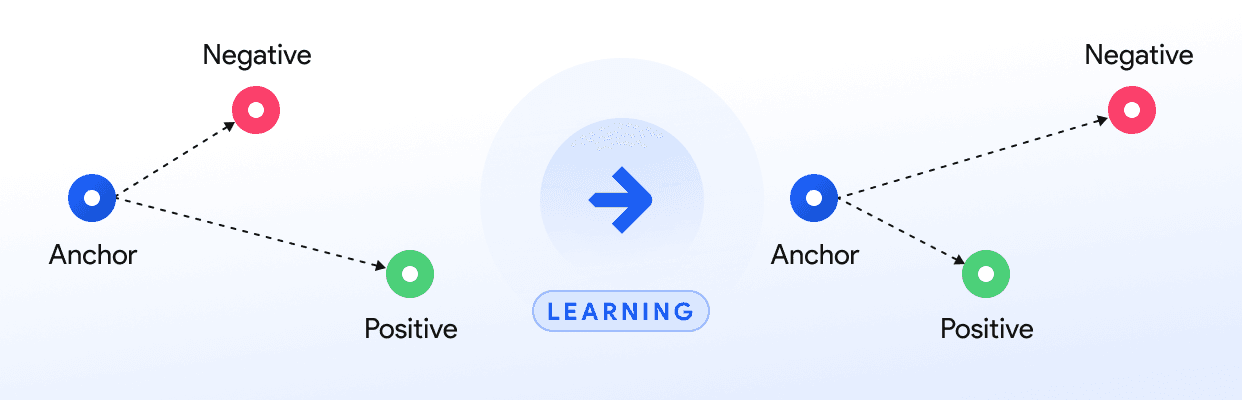
Triplet Loss approach
Triplet loss is very popular due to its simplicity and intuitiveness. It is based on three elements: an anchor image, a positive image, and a negative one. The anchor represents a reference. The positive image belongs to the same class as the anchor, and the negative image is from a different class.
Using Triplet loss, the model is trained so that the Euclidean distance between the anchor and positive images decreases, while the distance between the anchor and negatives increases.
However, it has its defects. Triplet loss is indifferent to class variation of the features. It is difficult to guarantee that samples with similar labels are pulled together. Also, choosing useful triplets to train can be quite problematic.
ArcFace approach
ArcFace has a different approach and was developed more recently. It derives from other losses, such as SphereFace and CosFace, both of which are built from Softmax loss.
These losses take care of intraclass similarity and interclass diversity in embeddings. They distribute embeddings on a hypersphere, giving them a geometrical interpretation. ArcFace adds an angular margin penalty in its structure to go one step further on the benefits these losses have to offer.
The distance between embeddings of the same class is smaller, whilst embeddings of different classes fall further apart.
You can check out a complete explanation of how this loss is built here.
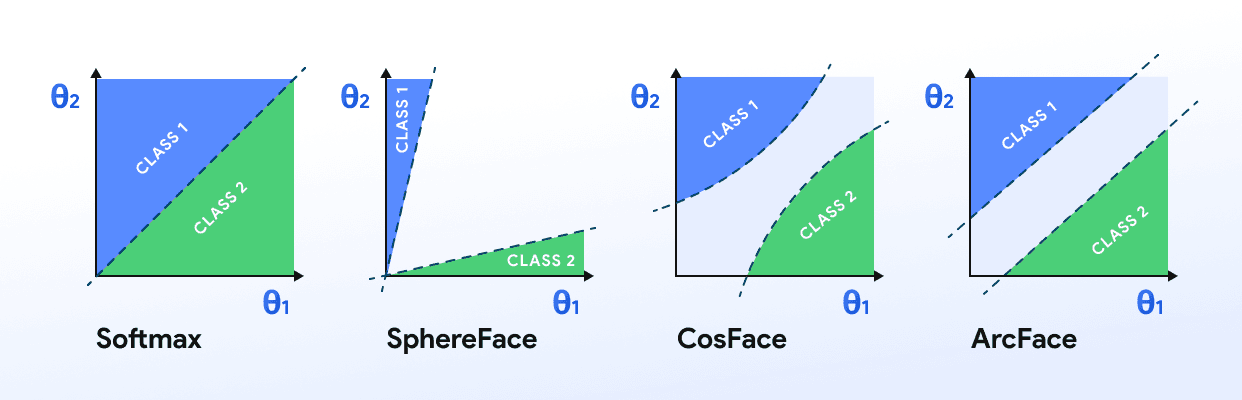
ArcFace proved to perform better than SphereFace and CosFace, and contrastive approaches such as Triplet Loss. However, it is not as intuitive as other loss functions, with which you can also achieve good results.
PyTorch Metric Learning is an excellent fit to carry out the experiments needed to compare these two losses.
We’ll mention the parts of the library we used along the way but won’t get into details due to the fact they are all very well explained in the library’s documentation. In this way, with all the corresponding references you can easily replicate the process.
We worked on a whole train/test workflow, based on the example given on the MetricLossOnly trainer. Here, we defined our dataset and initialized the ResNet and a Fully Connected Layer to decrease the embeddings’ dimension, in this case, to 512.
Keep in mind that we are using a different dataset than the one presented in the example. You can download the TinyImageNet dataset by clicking on this link, and get the code to load the dataset from our public repository.
We also initialized the losses, which are already built in PyTorch Metric Learning. The library has lots of tools that come in very handy. One of them is the miner. It does the dirty work of picking data points to train the model.
For instance, it solves the problem of distinguishing anchor, positive and negative triplets to feed the model when using Triplet loss.
In this case, we used the MultiSimilarityMiner. For this experiment, we used the parameters’ default values and picked out Adam optimizers and MPerClassSampler, which were recommended in the example.
However, in a real scenario, we suggest you try out the different optimizers and samplers. They can be easily swapped and may lead you to better results. Also, the GlobalEmbeddingSpaceTester is an excellent tool to use in these cases. It takes care of accuracy calculation, embedding plots, and saving of models and checkpoints. Being integrated with Tensorboard, it makes monitoring the training progress really simple.
We trained the model twice, one with each loss, for 150 epochs, on a 2080ti GPU. The dataset was composed of 100.000 images, which we divided into batches of 64.
Each training took approximately 3 hours and 50 minutes. The results we obtained were quite interesting.
To analyze them, we measured the accuracies provided by the AccuracyCalculator, with the parameter k in "max_bin_count". The default accuracies the library offers are the following:
- Adjusted Mutual Information (AMI)
- Normalized Mutual Information (NMI)
- Mean Average Precision
- Mean Average Precision at R
- Mean Reciprocal Rank
- Precision at 1
- R precision
PyTorch Metric Learning provides documentation links to understand each one in the utils section of its documentation. One could also implement custom accuracies in the workflow.
On one hand, the Triplet loss scored better in both accuracies regarding mutual information (AMI and NMI). This means the embeddings obtained from Triplet loss give a better measure of the similarity between two clusters. Check out the graphs we obtained with the help of PML:

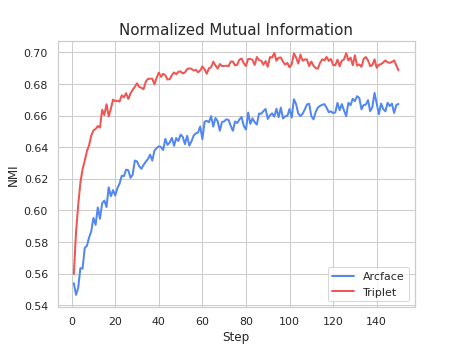
On the other hand, precision metrics were better in the ArcFace results. This makes sense with the theoretical framework we’ve seen before, where ArcFace is a newer loss with better results than Triplet loss. Once again, we have the results plotted on Tensorboard thanks to PML.




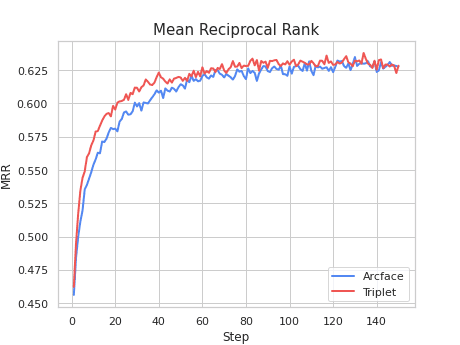
As you can see, using PyTorch Metric Learning is very easy. In just a few steps we were able to train a model twice and get quick insights of their results.
In addition, the implementation of the end_of_epoch_hook in our tester allows us to see the embeddings’ plots as we train our model. We could go on investigating all the gadgets the library has to offer, but we’ll leave some of the fun for you.
We hope this example serves you as a first step into the Metric Learning world, understanding and comparing two very different losses. Pytorch Metric Learning helped us experiment with Triplet loss and ArcFace loss in a very friendly way.
Whenever you face your next similarity challenge, don’t hesitate in using this library. PML makes Metric Learning more accessible, with great modules that have many practitioners’ nightmares already sorted out.
If you liked this article, check out the other entries on our blog!



